Hardware availability detection (HA)
High Availability (HA) and hardware fault tolerance#
There are several ways of achieving hardware redundancy and fault tolerance at an edge site.
Fundamentally there needs to be an elimination of the EVX edge appliance as a single point of failure.
Depending on the organisational network needs, this may be achieved with multiple devices and interfacing with the LAN or firewalls with a routing protocol, or a cluster acting as a virtual router.
Either of these setups mirrors the default configuration of connecting to multiple Network Fabric Routers (NFRs), thus achieving redundancy at every level of hardware.
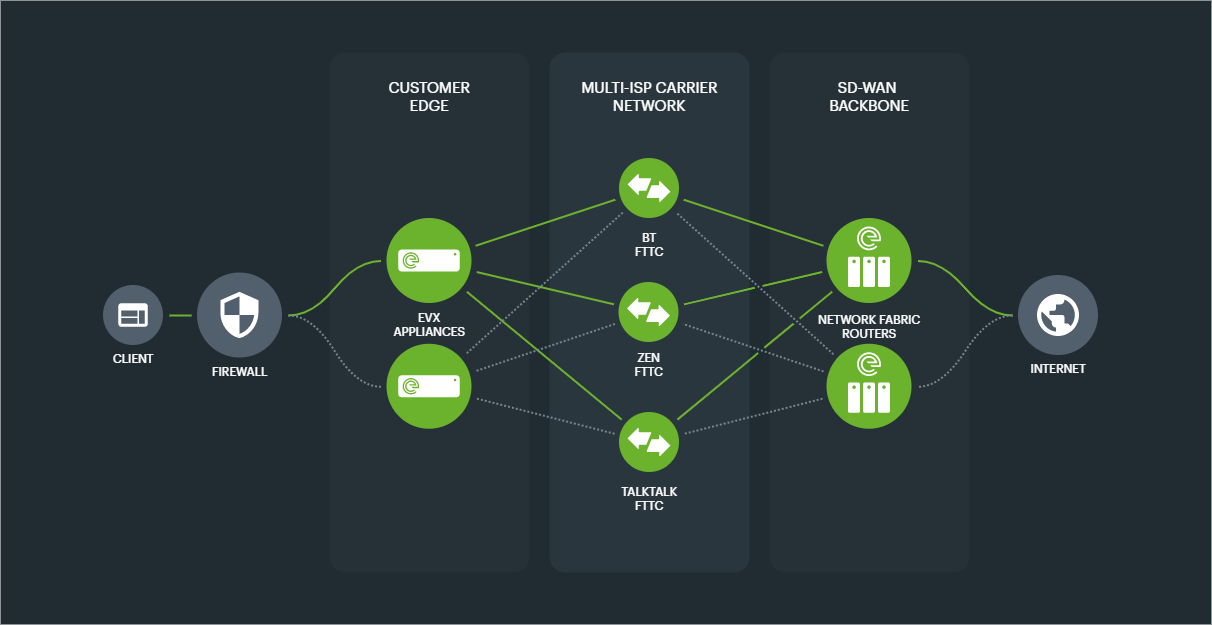
The INF allows for any network segmentation configuration, whether simple internet breakout or other more complex hypernet configurations to be made resilient at the CPE hardware level.
High Availability clusters using VRRP#
Using VRRP, or Virtual Router Redundancy Protocol, clusters of EVXs can be configured with floating, virtual IPs.
Each TAG connects to each corresponding NFR so that any combination of paths is possible during any component failure scenario.
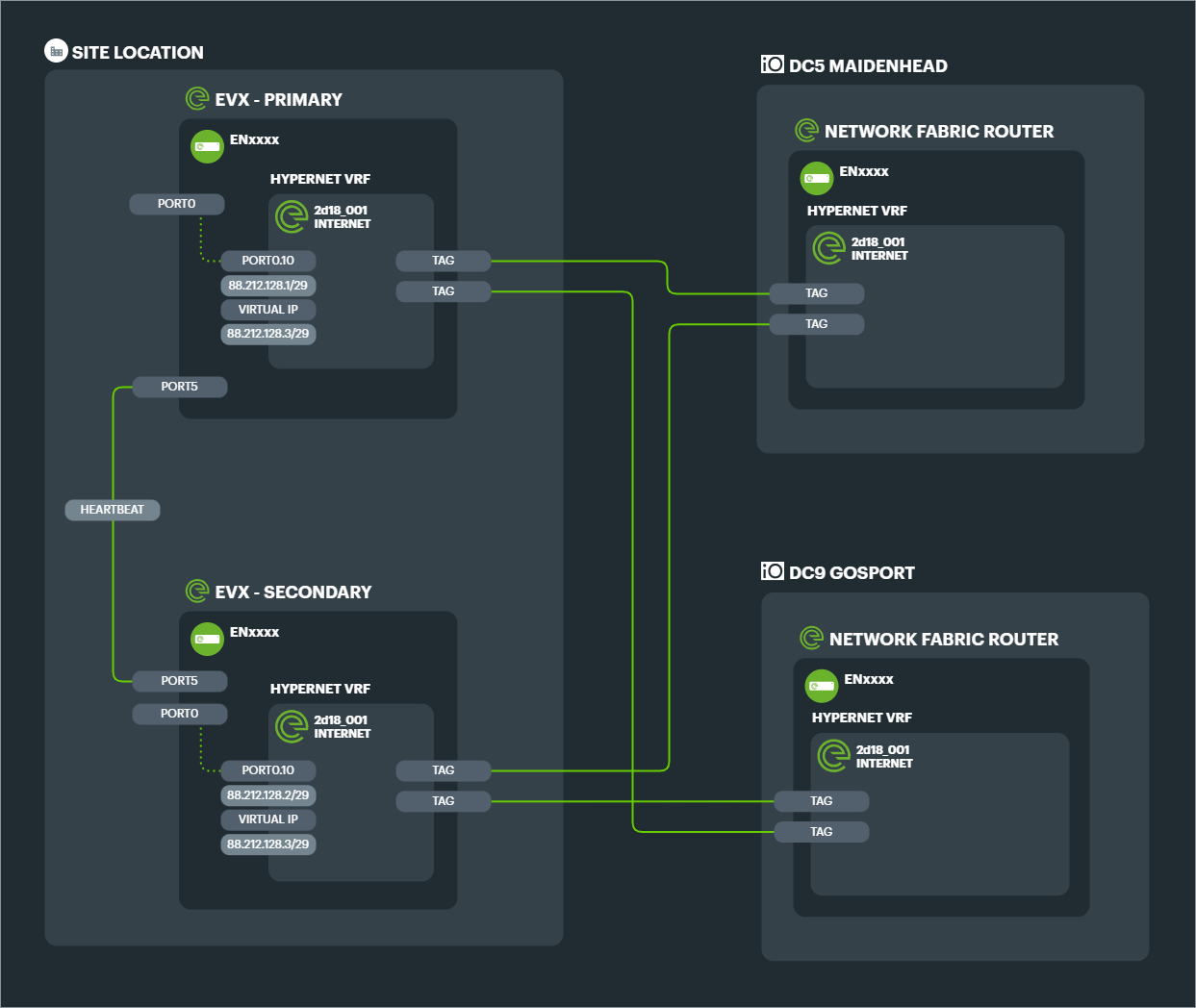
Typically the EVXs would be paired with redundancy devices on the LAN side.
Example: 2 Link aggregated connection with an HA pair of EVXs connected to an HA pair of local firewalls and switches.
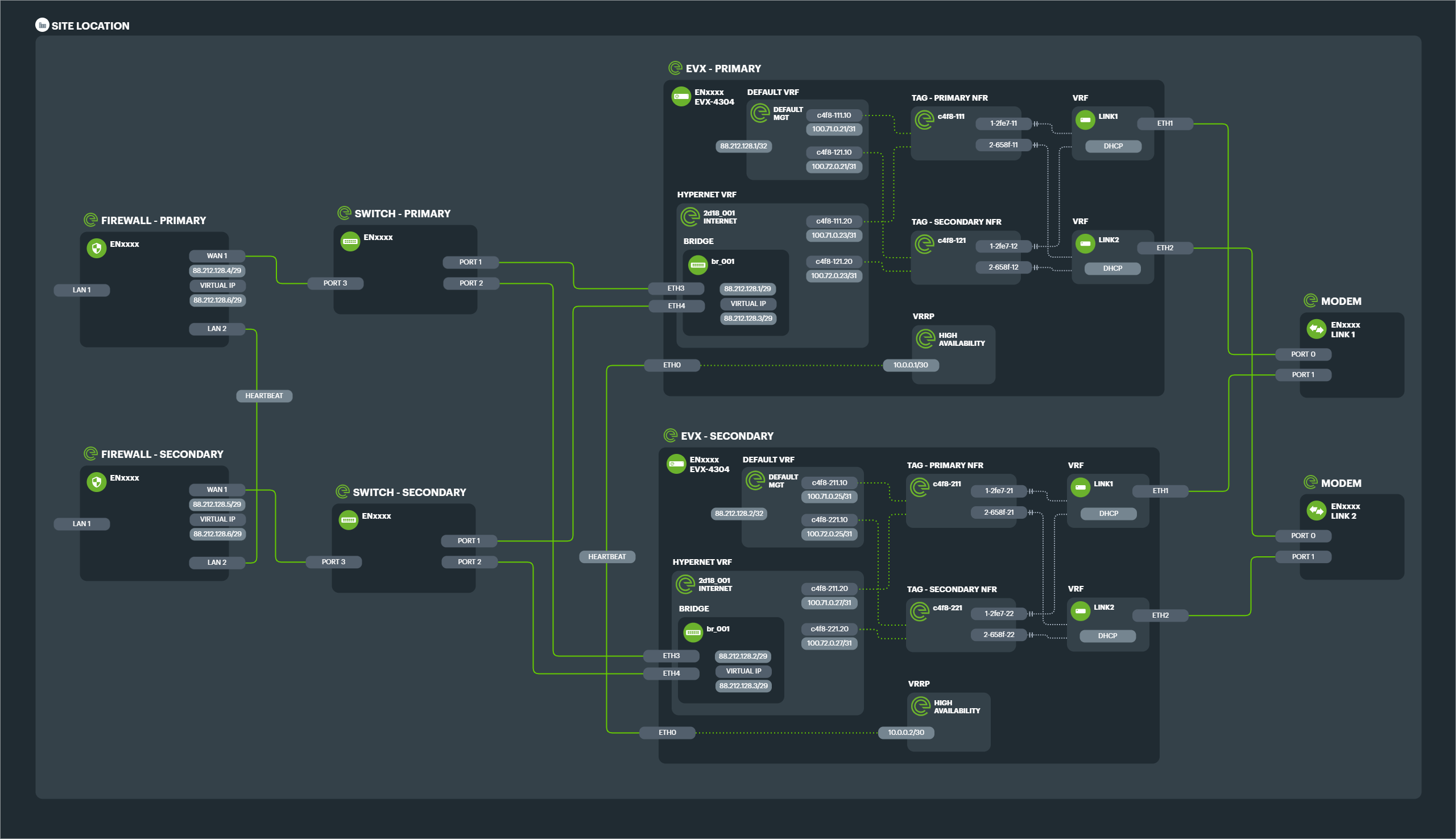
EVXs in the cluster are connected together by a Heartbeat cable. If clusters of more than two are required, then a switch cluster can be implemented between the EVX cluster to allow for scaling.
High Availability clusters using BGP#
Through the use of a routing protocol such as BGP or OSPF, relationships can be established between EVXs (either on their own or in a cluster) to devices managed by the customer. Routes can then be propagated and used depending on the availability of nodes in the cluster on both sides of the relationship.
No heartbeat cable or ports are required in this configuration as the setup is entirely decentralised.
Example: A pair of firewalls connected to a pair of EVXs, with an intermediate network of a pair of switches.
Each firewall would have a BGP relationship with each EVX so that they could send and receive routes. If any device were to fail, then the routing protocol configuration would kick in and send traffic down the next available path.
In this setup, whoever manages the firewalls has the greatest control over the hypernet and which paths to take. In this instance, with the customer managing the firewalls, they have the power (as long as it was determined as a need originally) to create and destroy different subnets and even move them between any sites that use this BGP configuration, without needing Evolving Networks to make changes.
Likewise, the customer has the power to choose which EVX to route traffic to.
This gives a great deal of flexibility for testing proof of concept network changes, troubleshooting and working around component faults quickly.